My Key Takeaways from DevFest New Delhi 2023
My Learning and Insights from DevFest New Delhi 2023 Talks

curious 🚀👨💻• SIH'23 Winner 🏆 • SDE Intern Lunacal • Ex SDE Intern Mojo Technologies • Lead Dev @SDC_USS • core @gdsc_usar
In The Daily Busy Life of New Delhi on the 7th of October, 2023, I found myself between a Community of like-minded tech enthusiasts at DevFest New Delhi 2023. It was a day packed with talks, workshops, and a fair share of quirks to keep things interesting. As I navigated through, I attended various talks that promised to demystify the world of technology.
In this blog, I'll share the key takeaways from these talks and give you a glimpse into the knowledge shared on the day. Now, here's the deal – grab your coffee, because trust me, you're gonna need it! Tech talks can be Mind Boggling, and caffeine is our trusty partner on this adventure! So, sit back, relax, and let's dive into the tech wonderland. 🚀☕😄

Talk 1: Where's my Cloud? - Cloud in the Era of GenAI [Cloud Track]
by Pranay Nanda

Pranay Nanda delivered an engaging and informative presentation on the fundamental concepts of cloud computing for beginners. As the opening talk in the cloud track, he successfully captured and maintained the audience's attention throughout his session. Pranay underscored the pivotal role of artificial intelligence (AI) in shaping the future of cloud computing.
He also delved into the perpetual demand for infrastructure, highlighting that, despite AI's remarkable advancements, the essential need for reliable and efficient cloud infrastructure will persist. He outlined how AI can act as a powerful tool for learning about cloud technologies, empowering individuals to expand their knowledge by simply asking questions. This integration of AI into the learning process can greatly accelerate skill development and foster a deeper understanding of cloud systems.
A pivotal question that often arises in discussions about AI: "What About My Job?" Pranay addressed this concern with his perspective, assuring the audience that their jobs would not be replaced but rather assisted by AI and it will help Cloud Operators to make better decisions. He Quoted "AI will stay but the focus has to change".

During the presentation, Pranay introduced Vector Databases, shedding light on its remarkable features, such as its high scalability and low latency of less than 10 milliseconds. This technology indicates the boundless possibilities in cloud computing that await exploration. As DevFest continued, this talk set the tone for an event filled with innovation and forward-thinking ideas.
Talk 2: Data Portability in the Cloud

Jatin K Malik, a seasoned Principal Software Engineer at Atlassian, shared his insights on the crucial topic of data portability in the cloud. Drawing from his extensive experience with renowned companies such as Uber, Adobe, and Shuttle, Jatin began his presentation with an engaging quiz and cool swag giveaway. This quiz Tested the audience's knowledge of fundamental terms like "servers," "data centers," and "cloud," helping to set the stage for a deeper understanding of the cloud ecosystem. Upon concluding the quiz, Jatin presented his definition which is "A server is a component of a data center, and a data center offered as a service constitutes the cloud."
The presentation then transitioned into a discussion of the motivations for utilizing cloud technology, underlining two primary factors: cost-effectiveness and security. He shed light on why the cloud has become a central component of modern tech and why it's always a great choice to choose the cloud rather than building your own data center and servers.
Moving on, Jatin dived into the concept of data portability, emphasizing the critical role it plays in enterprise operations. He also addressed the complex challenges associated with data portability, including data residency and the data laws that exist across different countries because at last, the end goal is that data shall be safe/secure and retrievable.
One notable highlight of the presentation was the introduction of the acronym BRIE, which stands for "Backups, Restore, Import, and Export." Jatin dissected each term, providing the audience with a comprehensive understanding of these data portability functions.
Backups: Backups involve duplicating data to protect against loss and enable recovery in case of data issues or disasters.
Restore: Restoration is the process of recovering data from backups to return it to its original state after data loss or corruption.
Import: Data import is the action of bringing external data into a system or application, often used for data migration or consolidation.
Export: Data export is the process of moving data out of a system or application, useful for compliance, sharing, or creating local backups.
Later at an interactive segment, he posed an intriguing question to the audience: What's the fastest way to transfer 3 terabytes of data? The surprising and unpredictable answer—pigeons—captured the audience's attention. The notion that a pigeon could be faster than the internet for such transfers was both amusing and unpredictable for me at least. He introduced two cutting-edge solutions for large-scale data transfers in the cloud: AWS Snowmobile and Google Cloud Transfer Appliance. These services, designed for exabyte-scale data transfers, address the ever-growing demand for efficient data portability.
In summary, Jatin K Malik's talk offered a concise yet informative perspective on data portability in the cloud, leaving the audience with a deeper appreciation of this aspect of technology.
Talk 3: Next-Gen Cloud Native Dev Environments
by Pushkar Sharan

Pushkar Sharan, a seasoned cloud enthusiast with over 15 years of experience in the industry, provided a compelling discussion on the future of cloud-native development environments. He kicked off the session by presenting a comprehensive flowchart, illustrating Pipeline about how developers interact with Continuous Integration/Continuous Deployment (CI/CD) pipelines and Git to deploy applications on diverse servers. This visual representation set the stage for an insightful exploration of cloud-native development practices.
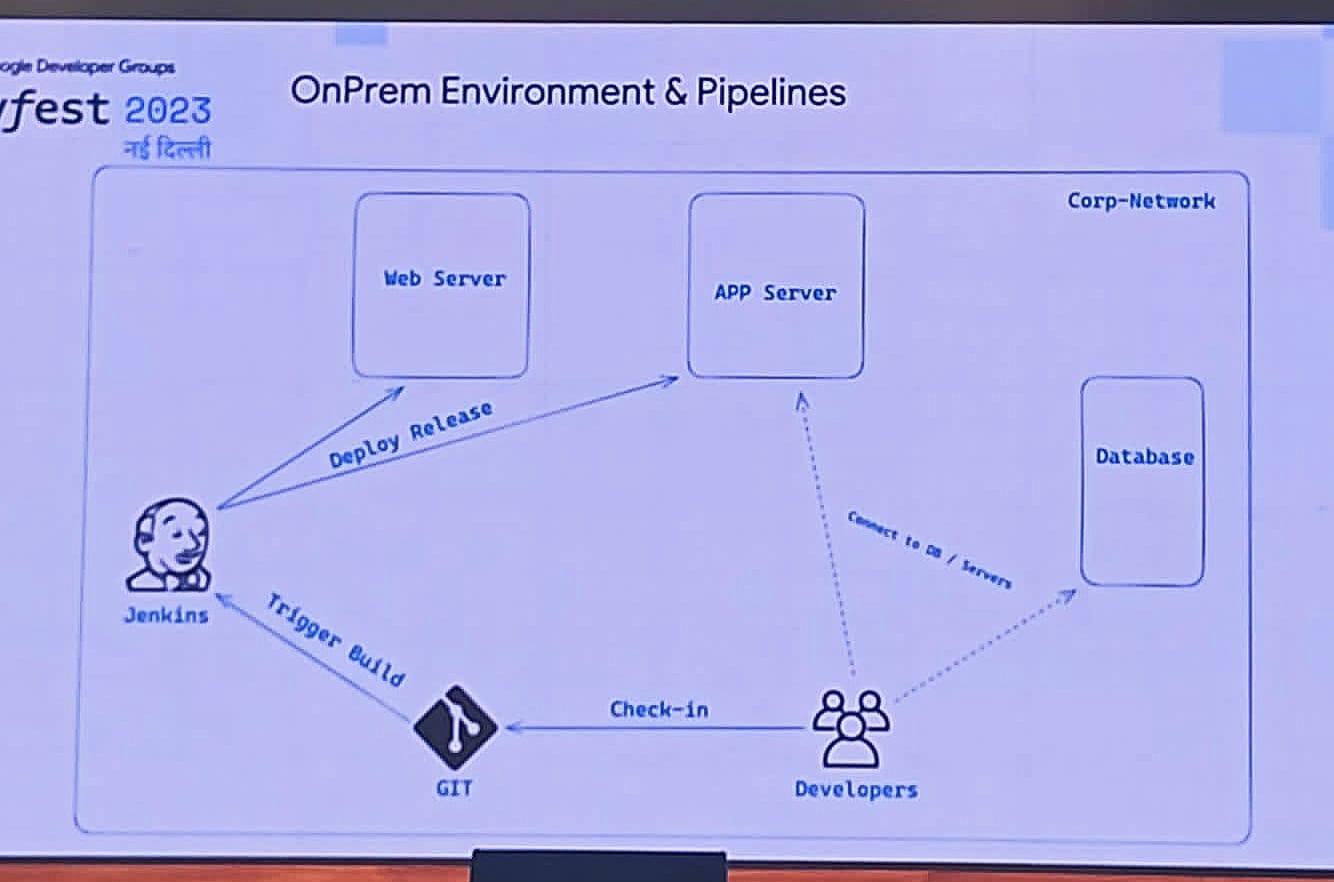
Pushkar discussed the difficulties that come with deploying cloud-native apps. These challenges involve making sure the apps can handle growth, handling lots of smaller services, keeping data in sync, and effectively managing containers. These challenges highlight how complex things can get for developers in the cloud-native world.
One of the Main highlights of Pushkar's talk was his introduction of cloud workstations. These workstations offer a fully manageable and integrated developer environment hosted on Google Cloud, featuring built-in security and a high degree of customization. What sets cloud workstations apart is their accessibility; developers can tap into them from anywhere, fostering seamless collaboration. Every team member operates on the same codebase within the same environment, effectively eliminating the compatibility issues stemming from varying system versions. This remarkable feature aligns with the concept of a cloud-based Integrated Development Environment (IDE), and the beauty of it is that you can scale it to accommodate as many workstations as needed to support your team's productivity. This makes things much better for both admin and developer experience,
Moreover, he shed light on the prospect of deploying applications directly to Kubernetes with AI support in these workstations. AI-supported deployment to Kubernetes showcases a promising direction for developers
He also substantiated his insights by referencing Loreal's successful migration to cloud workstations. This real-world example underlines the practicality of adopting such cloud-native development environments, demonstrating that they are not just theoretical concepts but viable solutions for industry leaders.
Talk 4: LLM and ChatGPT [ ML + Security Track ]
by Shivay Lamba

In This Talk, Shivay Lamba provided a comprehensive overview of AI in 2023, with a focus on cutting-edge technologies like ChatGPT, Bard, Palm, and more. He commenced his presentation by delving into the world of Large Language Models (LLMs), emphasizing the remarkable capabilities of these statistical language models trained on vast datasets.
He introduced various LLMs, including Palm2, GPT-4, LLaMA, and the Falcon series, providing a glimpse of the rapid advancements and diversity in this field. These models represent the forefront of AI innovation, capable of understanding and generating human-like text across an array of applications.
A significant portion of his talk was dedicated to Keras, an open-source library renowned for its versatility in loading and fine-tuning pre-trained models. Shivay's discussion shed light on how developers can use the power of Keras to adapt these models to their specific requirements and open up vast possibilities in AI application development. Furthermore, Shivay addressed the challenges associated with LLMs. He pointed out that while these models are trained offline on enormous datasets, they lack real-time awareness of the latest information. This limitation is a crucial consideration when utilizing LLMs for tasks requiring up-to-the-minute data.
Shivay also touched upon the concept of Retrieval Augmented Generation (RAG) which is an AI framework for improving the quality of LLM-generated responses by grounding the model on external sources of knowledge to supplement the LLM’s internal representation of information. It ensures that the model has access to the most current, reliable facts, and You can cross-question a model’s answers with the original content so you can see what it is basing its answer on.
In summary, Shivay Lamba's Talk highlighted AI's exciting progress, spotlighting LLMs and Keras in model development. He also stressed LLM challenges and the Retrieval Augmented Generation for smarter, more adaptable AI in our ever-changing digital world.
Talk 5: Information Security in this Artificially Intelligent World
by Siddhant Tiwari

This talk was presented by Siddhant Tiwari and began by shedding light on a critical concept: Personal Identifiable Information (PII). PII includes any data that can be used to identify an individual, such as names, addresses, phone numbers, or even email addresses. Protecting PII is vital in the digital age, as its mishandling can lead to privacy breaches and identity theft.
Siddhant then delved into the vulnerabilities that can compromise security and can be a threat to Large Language Models (LLMs) and AI systems. Here's a simplified explanation of these threats:
Prompt Injections: This involves injecting malicious code into the input given to LLMs to manipulate their behavior. Essentially, it tricks the AI into producing harmful or biased output.
Insecure Output Handling: This pertains to how AI systems manage and provide their responses. If AI isn't programmed to handle the output securely, it may generate false or inappropriate information. For example, a chatbot offering medical advice without proper training could provide harmful suggestions.
Training Data Poisoning: During AI model training, data is used to teach the model how to respond to different inputs. If someone deliberately introduces incorrect or biased data into the training process, the AI could end up making decisions based on flawed information. This can be a major concern in fields like medical diagnosis.
Denial of Service: In this context, think of it as bombarding an AI system with excessive and resource-intensive requests. It's like sending so many tasks to an AI that it becomes overloaded and slows down, or even fails to provide the expected service. This disrupts user experiences and can incur high operational costs for service providers.
Permission Issues: To put it simply, AI models should only have access to certain parts of your data and resources. Just as you wouldn't want a random app on your phone to access your private messages, you wouldn't want AI systems accessing sensitive information like your email or social media accounts without permission.
Data Leakage: This occurs when an AI model unintentionally reveals confidential or sensitive information. For instance, if a chatbot accidentally shares your details during a conversation, it's considered data leakage. It's a significant privacy concern because it could expose personal information to unauthorized individuals.
Overreliance on LLMs: Relying too heavily on AI models, especially without human oversight, can lead to problems. This can include errors in generated content or a lack of accountability for AI-generated results. Overreliance can be seen in fields like content creation, where AI-generated articles or reports may not undergo sufficient human review.
Insecure Plugins: Just like how your computer's security can be compromised by installing malicious software, insecure plugins added to AI systems can expose vulnerabilities. These plugins are extensions that provide additional functionality to AI. If they are not properly secured, they can become gateways for unauthorized access or manipulation.
Siddhant's discussion highlighted the importance of not only understanding these threats but also implementing robust security measures to safeguard the integrity and reliability of AI systems in an increasingly AI-driven world.
Conclusion
So, dear reader, as we come to the end of this whirlwind tour through DevFest New Delhi 2023, I want to extend a heartfelt thank you for joining me on this journey. I hope you've gathered some important insights from this blog.
DevFest was a rollercoaster of knowledge, and honestly, it was just plain fun. Now, I wish I could tell you about all the talks I attended, but hey, I'm only human (or so I think). The notes for these are all I could manage, but oh, what a ride it was!
As we wrap up, I hope that every one of you gets a chance to attend a DevFest in the future. Trust me, it's an experience you won't want to miss. Until then, keep exploring the world of tech, keep learning, and keep those curious gears turning. Here's to more exciting adventures ahead! 🚀🤖🎉



